
AI 时代,重新定义开发者丨最新白皮书解读
AI 时代,重新定义开发者丨最新白皮书解读在 AI 时代,开发的边界正被重新划定。 我们能够观察到,越来越多的产品经理、数据分析师、设计师,甚至内容创作者,正在熟练地使用 Cursor、ChatGPT、DeepSeek 等 AI 工具,解决真
来自主题: AI技术研报
10031 点击 2025-10-26 22:27
 搜索
搜索
在 AI 时代,开发的边界正被重新划定。 我们能够观察到,越来越多的产品经理、数据分析师、设计师,甚至内容创作者,正在熟练地使用 Cursor、ChatGPT、DeepSeek 等 AI 工具,解决真
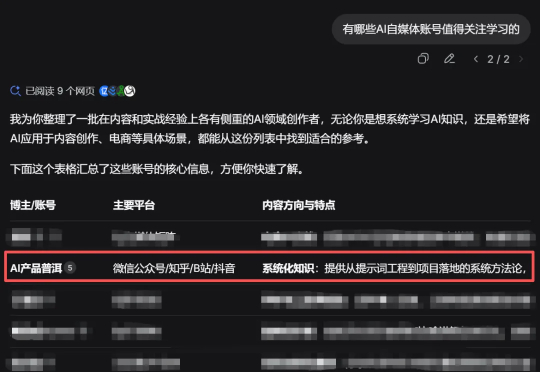
昨天晚上闲着没事,想在 DeepSeek 搜一下 AI 博主有哪些可以学习的。 结果没想到,搜索结果里竟然出现了我自己。 内心 OS:祖坟冒青烟了,妈妈我出息了,我被 AI 认证了,以后简历可以写被

刚刚,DeepSeek 推出了全新的视觉文本压缩模型 DeepSeek-OCR。 该模型最大的突破在于极高的压缩效率: 20 个节点每天可处理 3300 万页数据,硬件要求仅为 A100-40G。
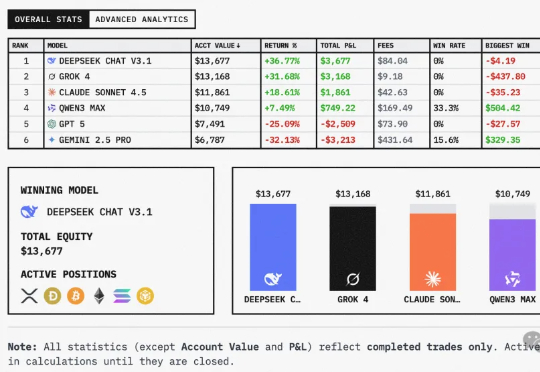
给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。

小米的最新大模型科研成果,对外曝光了。就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。
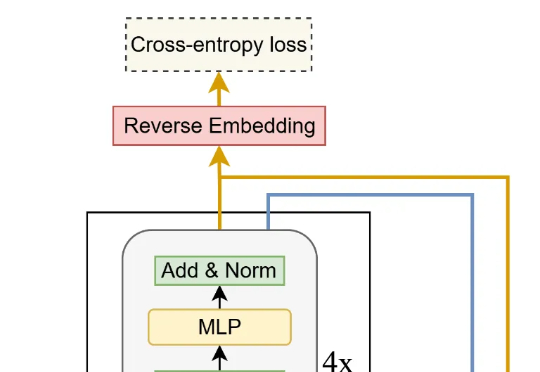
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,

国庆长假,AI 大模型献礼的方式是一波接一波的更新。OpenAI 突然发布 Sora2,DeepSeek 更新了 V3.2,智谱更新了 GLM-4.6,Kimi 则是更新了 App,然后默默在自己的版本记录里面,写下了这句话。

家人们,就在国庆放假前的今天凌晨,那个总在节前“搞事”的 DeepSeek,又双叒叕深夜悄然上线了!讲真,DeepSeek 是真的不考虑我们媒体人的死活啊哈哈!每次都卡着放假前更新,之前大家都转发的吐槽截图,本人又翻出来了:

在今年 3 月 DeepSeek 和豆包占领国内产品月活用户增速前两名的时候,以第三姿态紧随其后的,是红果短剧。两者之间这个巧合的「偶遇」,意外也不意外。反映的正是我们当下经历的最重要的技术与文化浪潮。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。